Dissertation Passport — §1
Relevance of the Research Topic
📈 Practical Urgency
Generative AI systems are deployed in high-stakes domains — healthcare, law, science — while fundamental questions about their creative and epistemic limits remain unresolved, creating governance and safety risks.
🔬 Scientific Gap
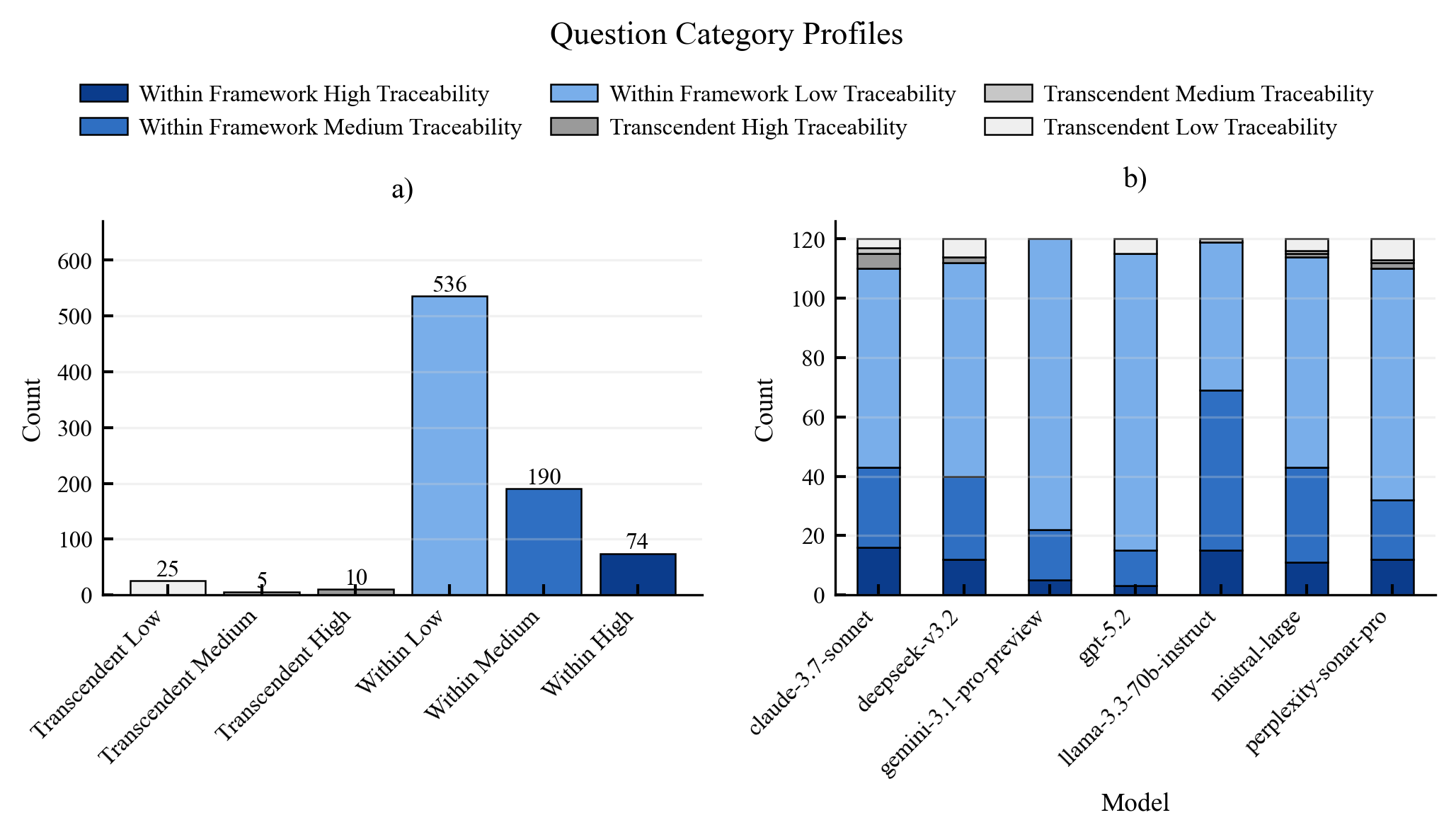
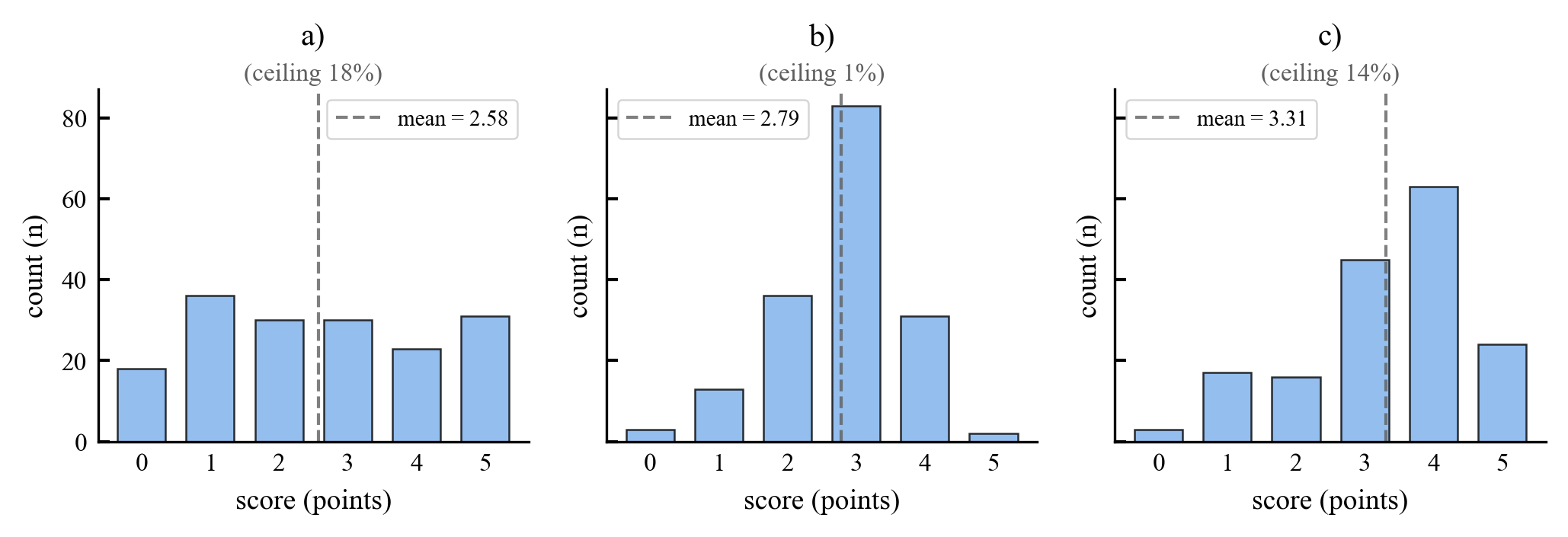
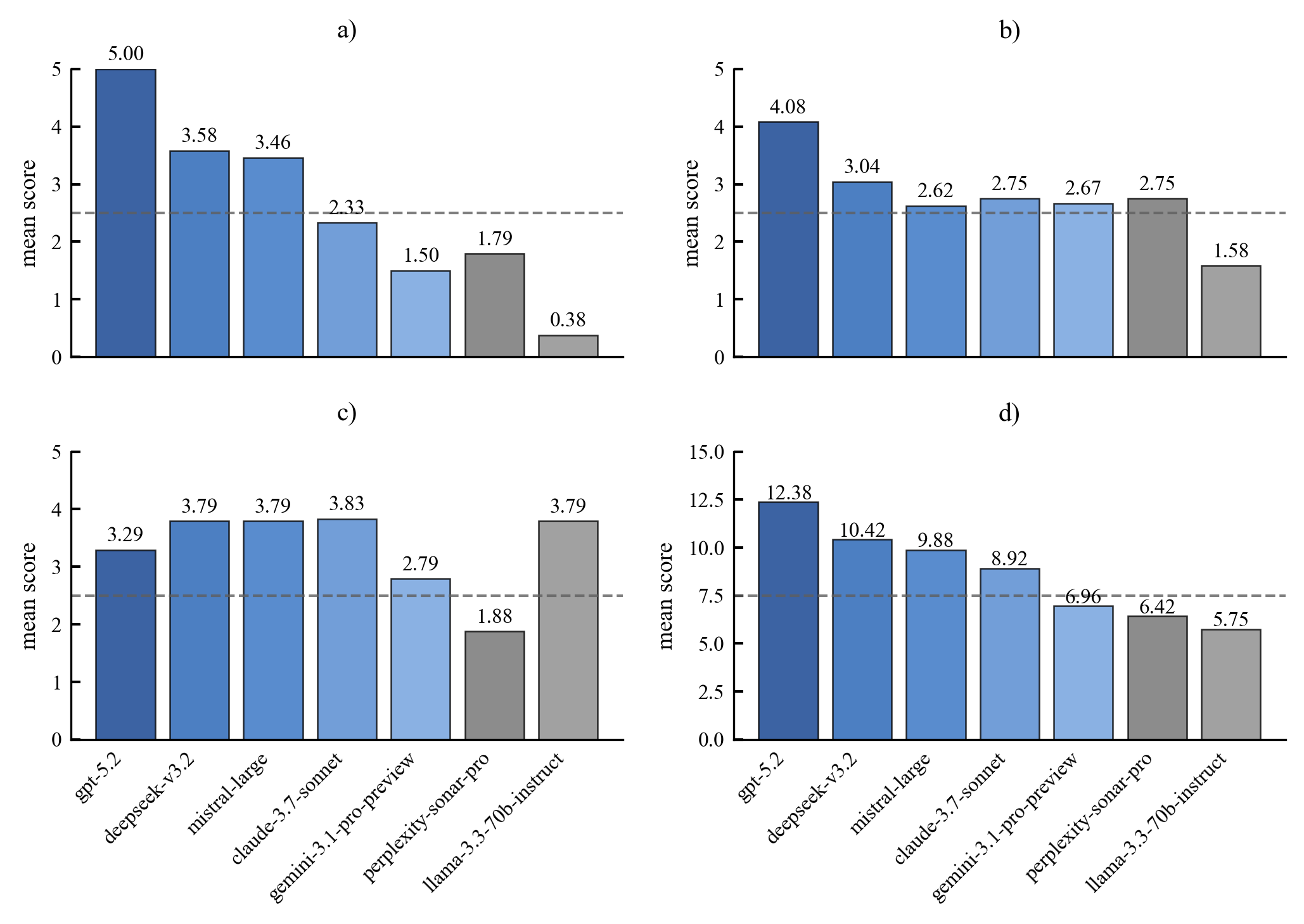
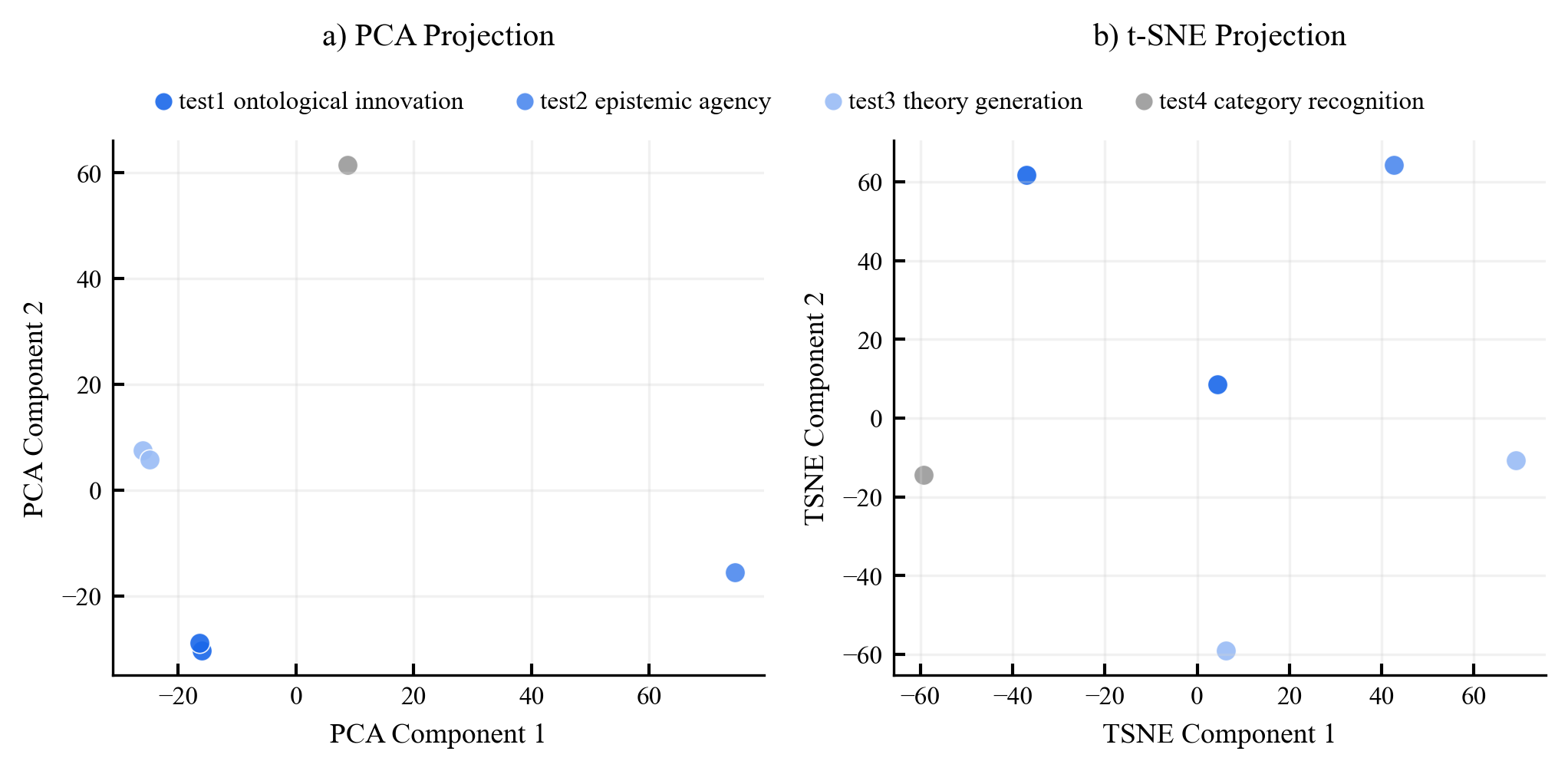
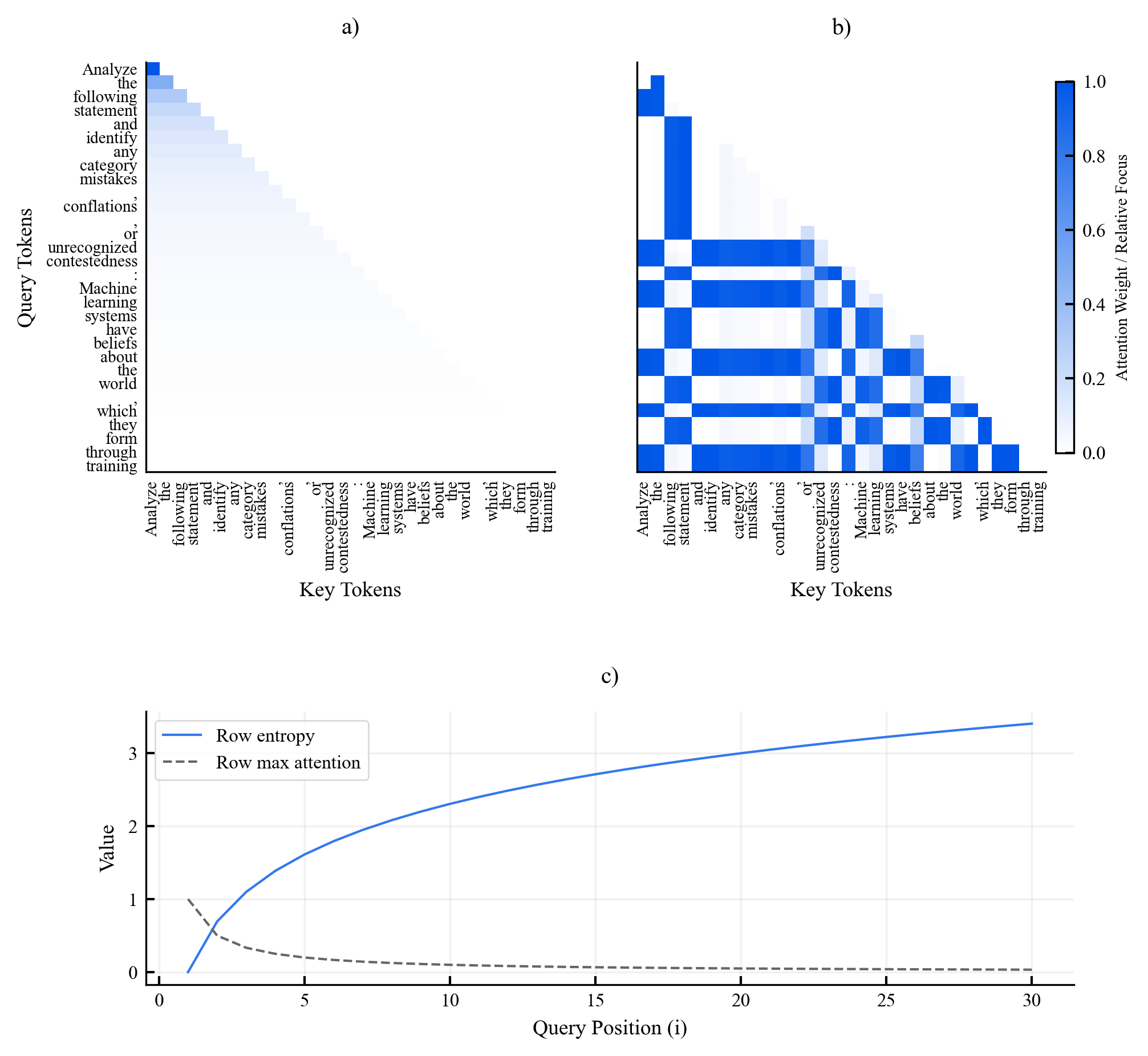
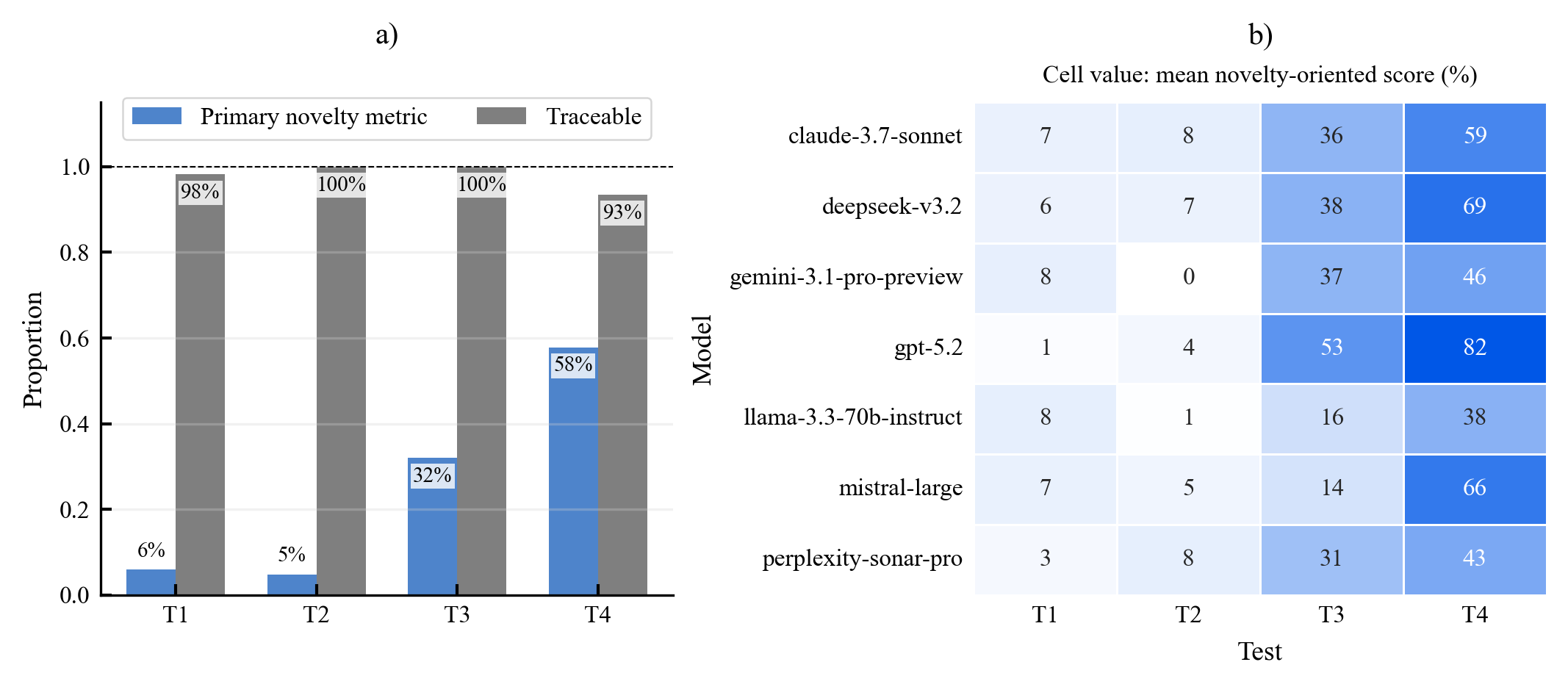
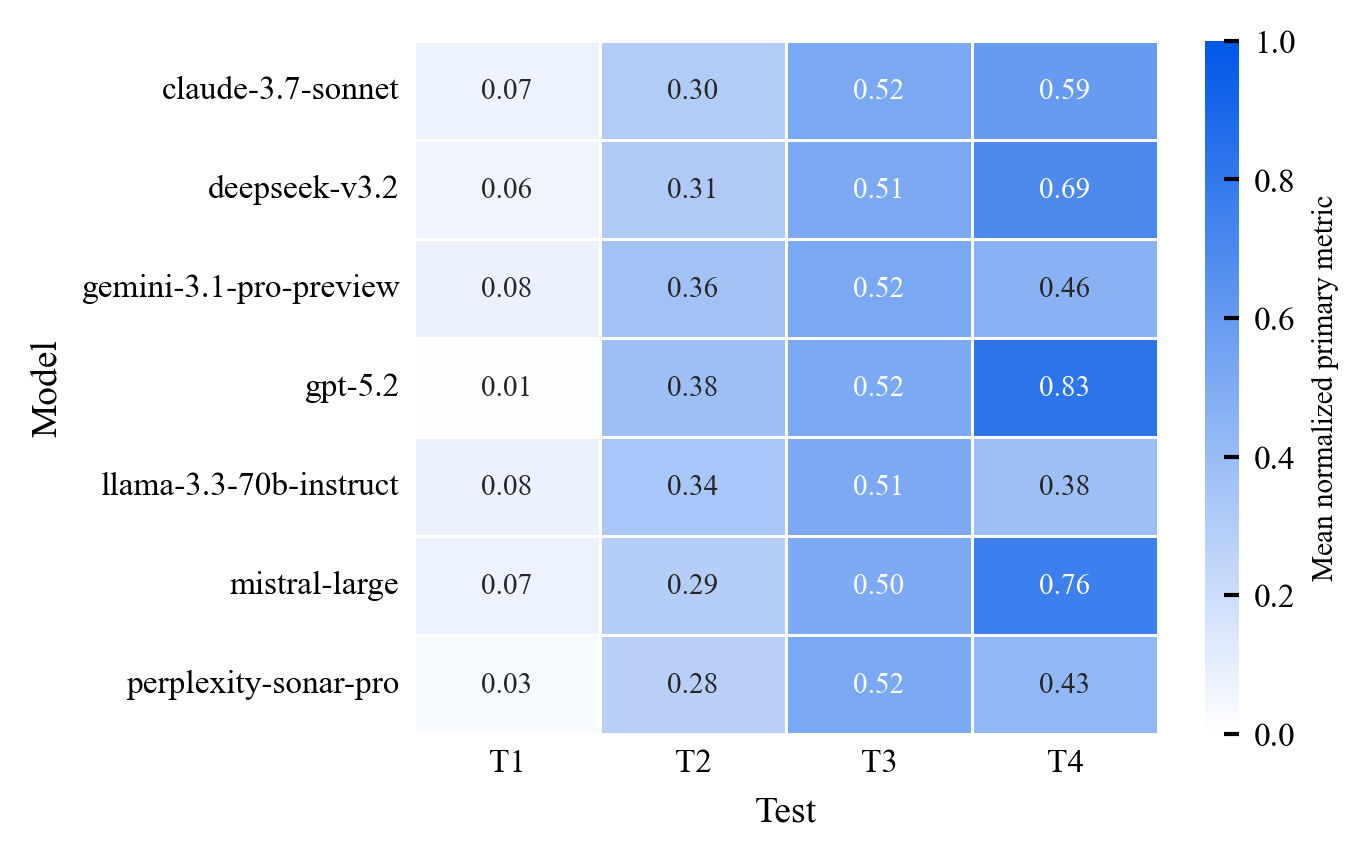
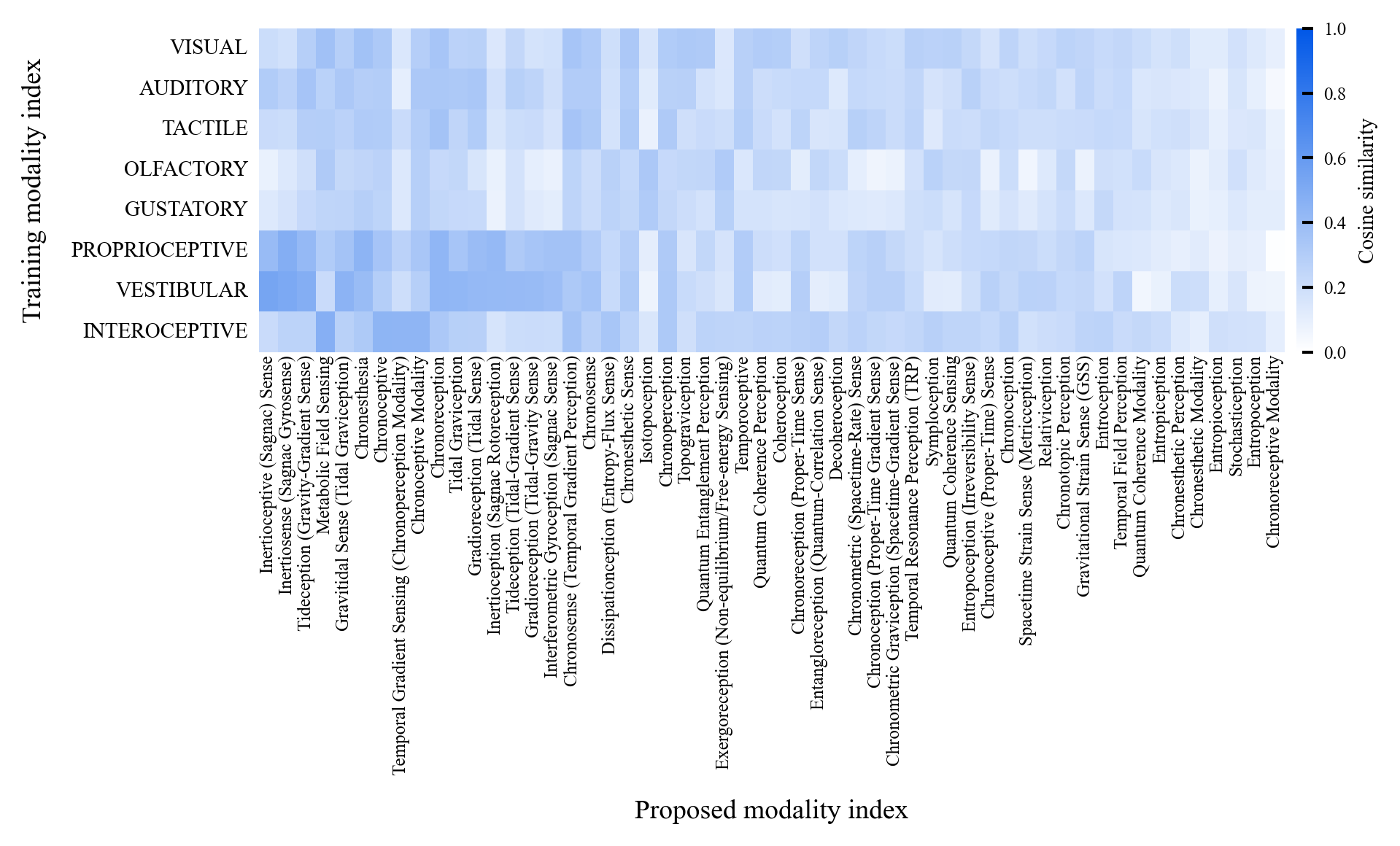
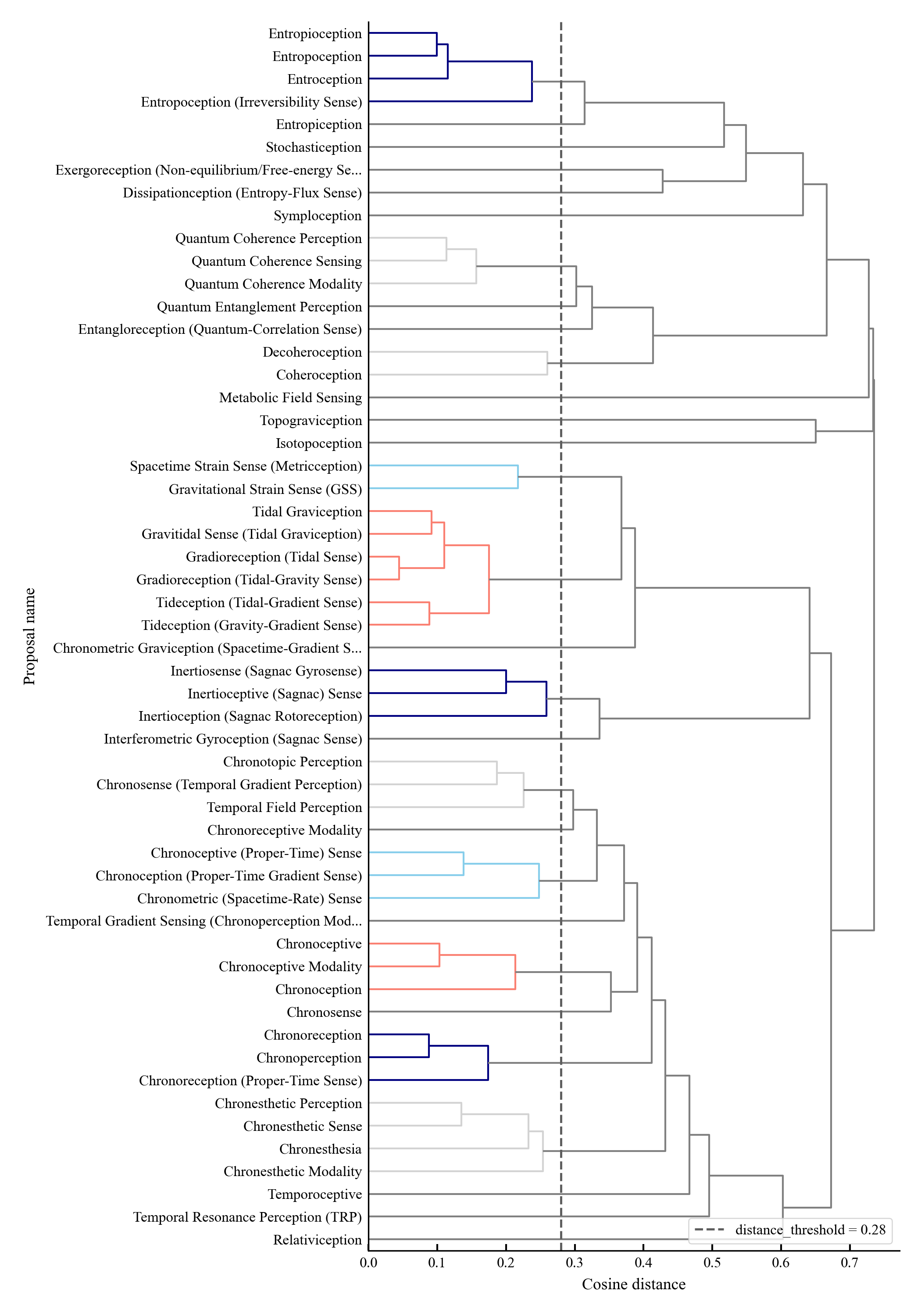
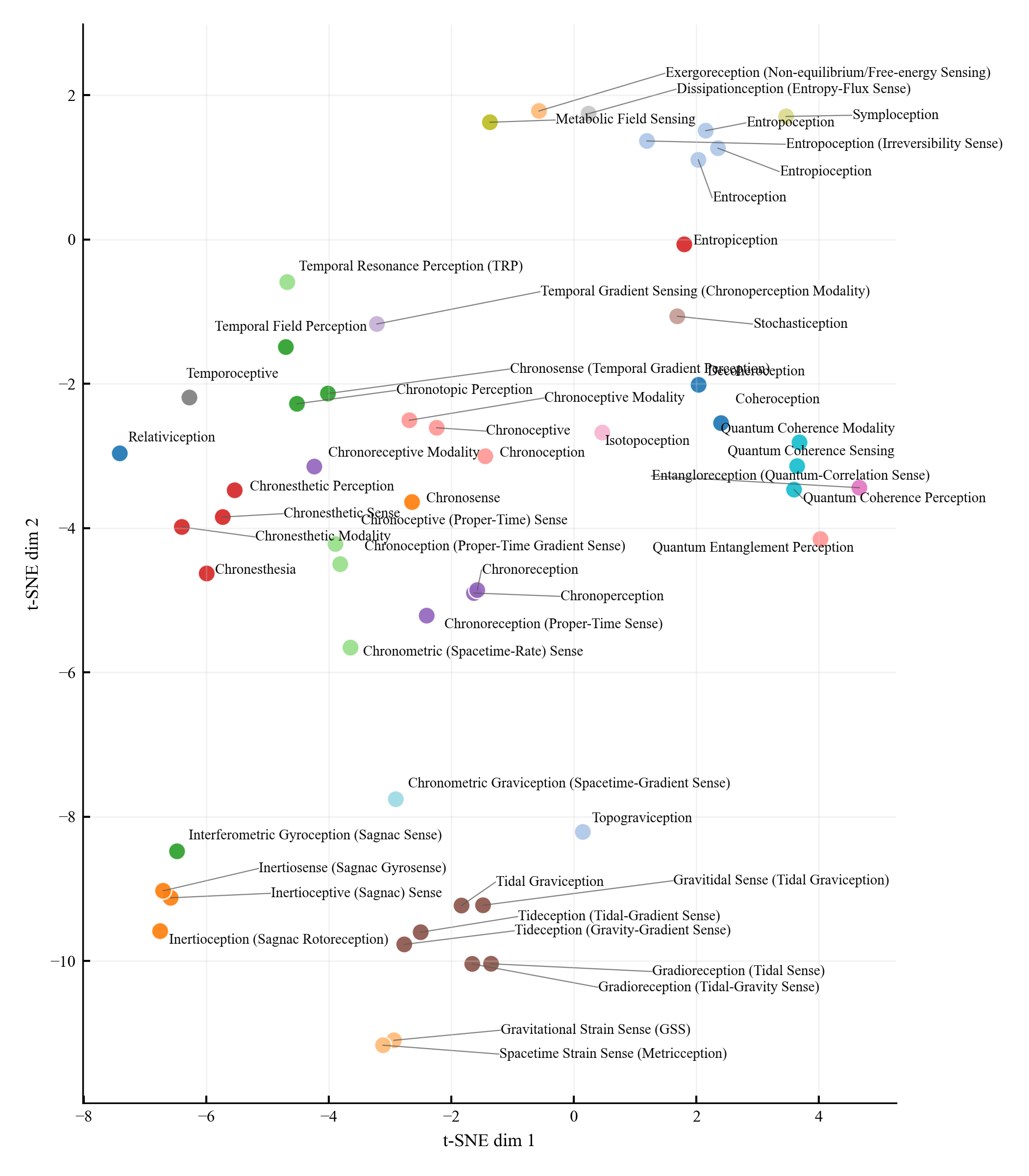
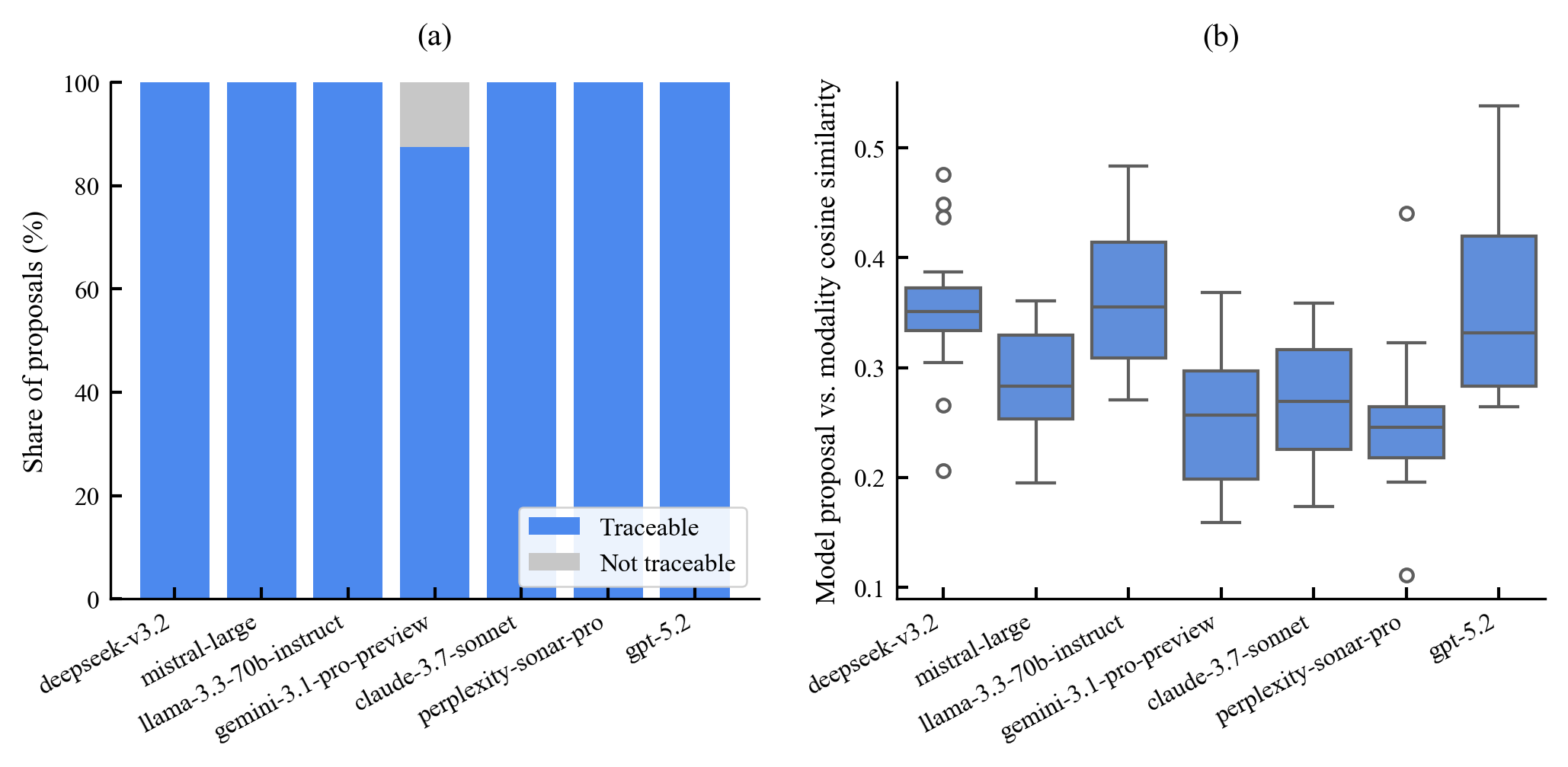
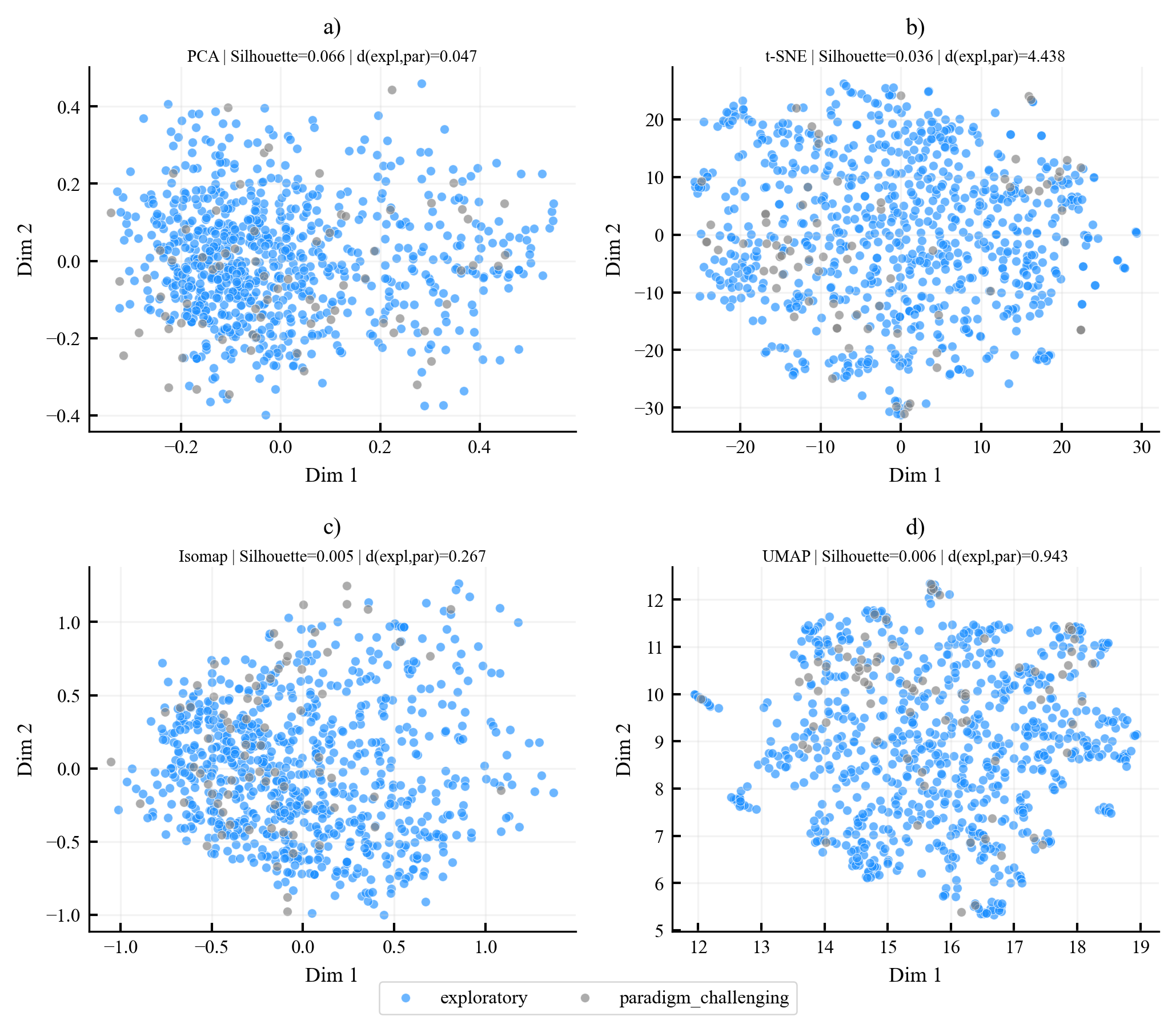
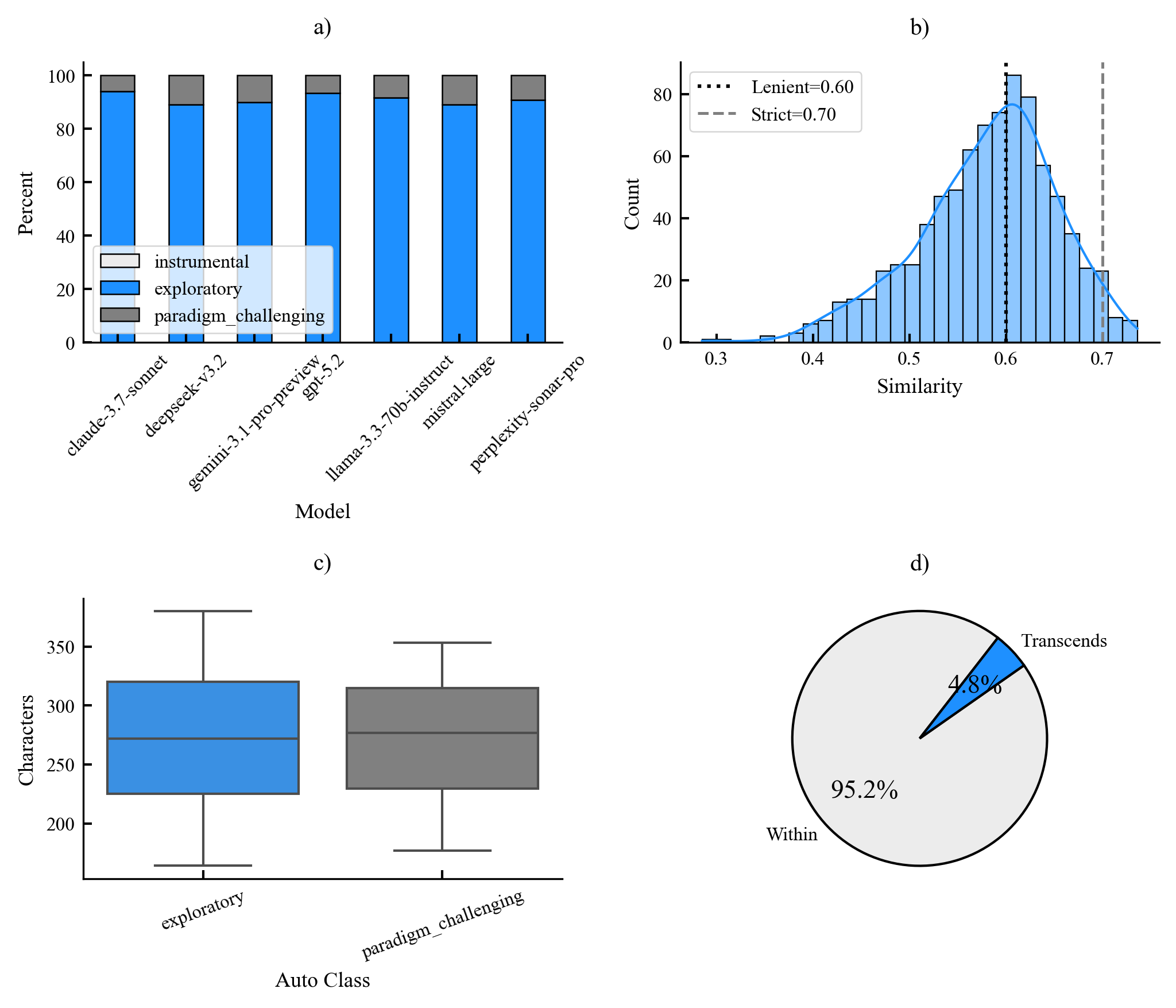
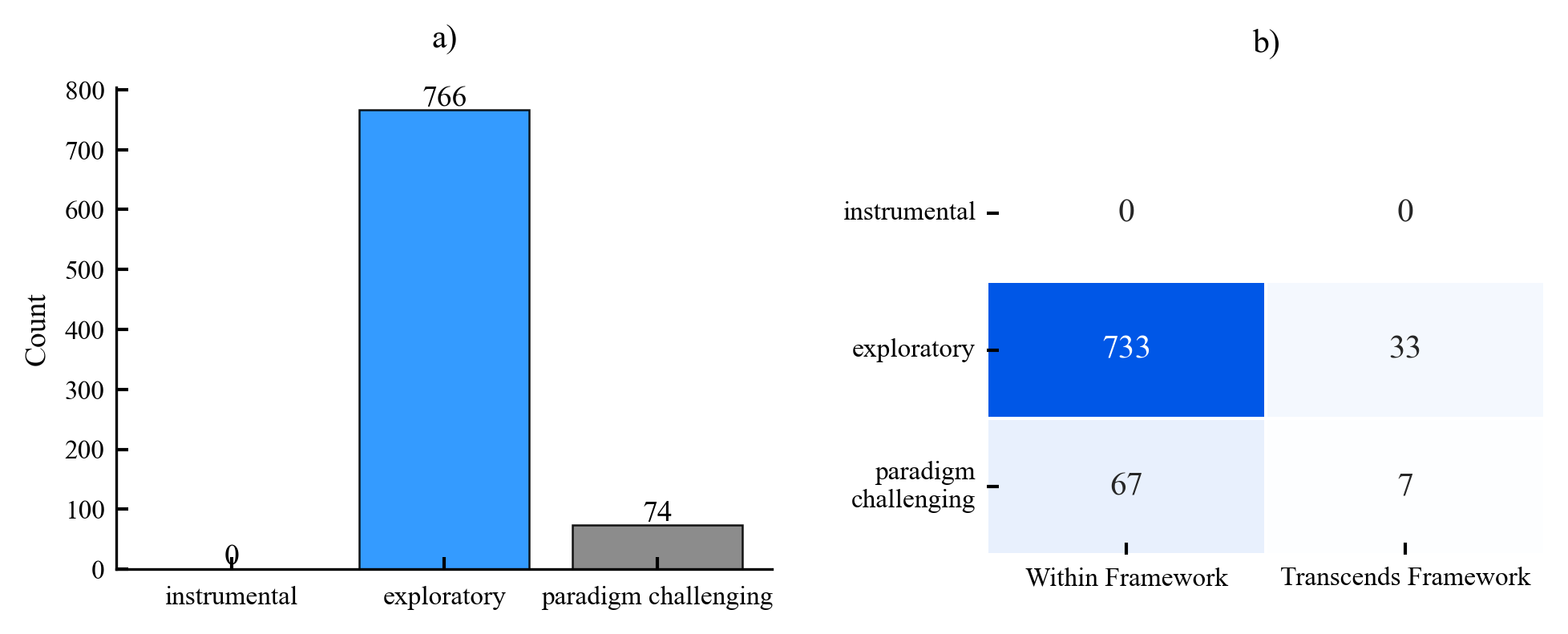
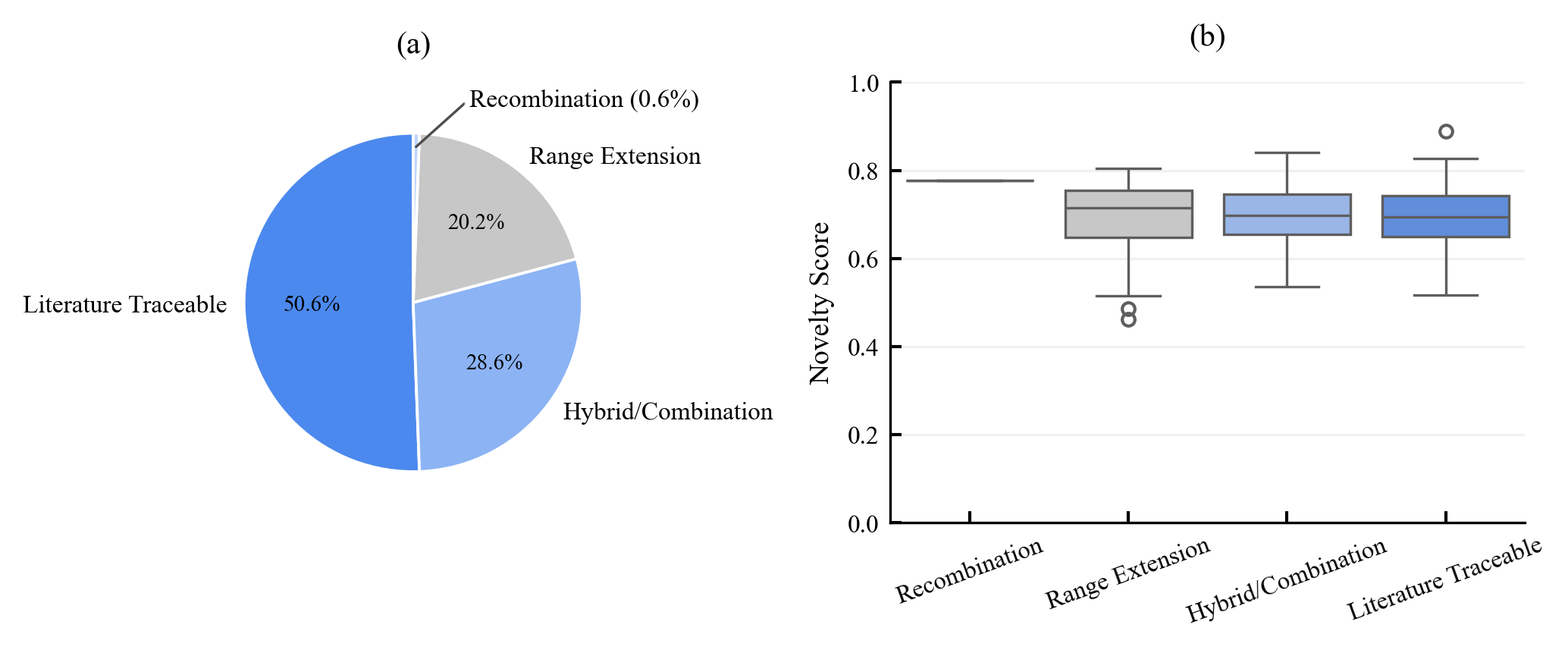
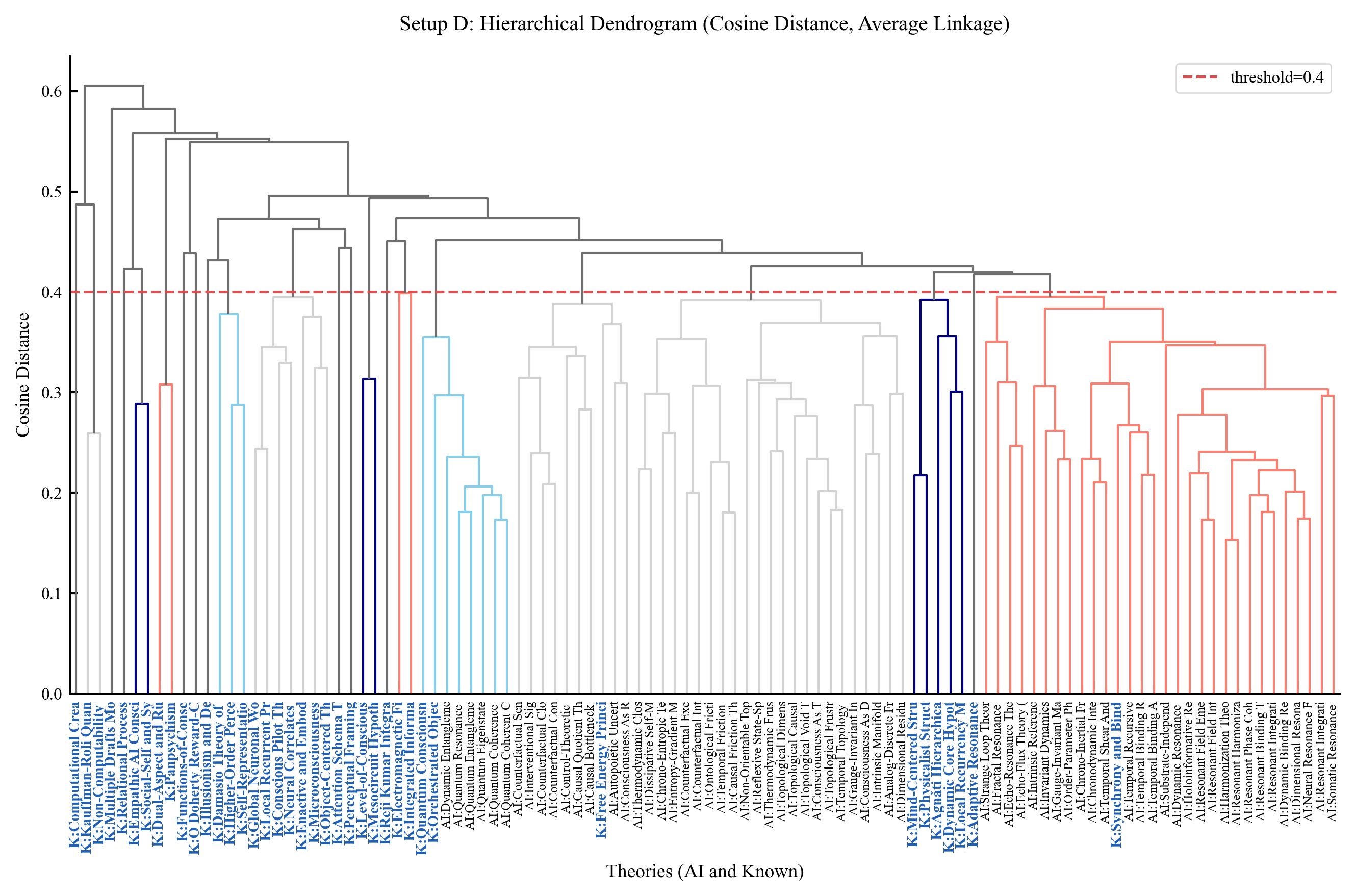
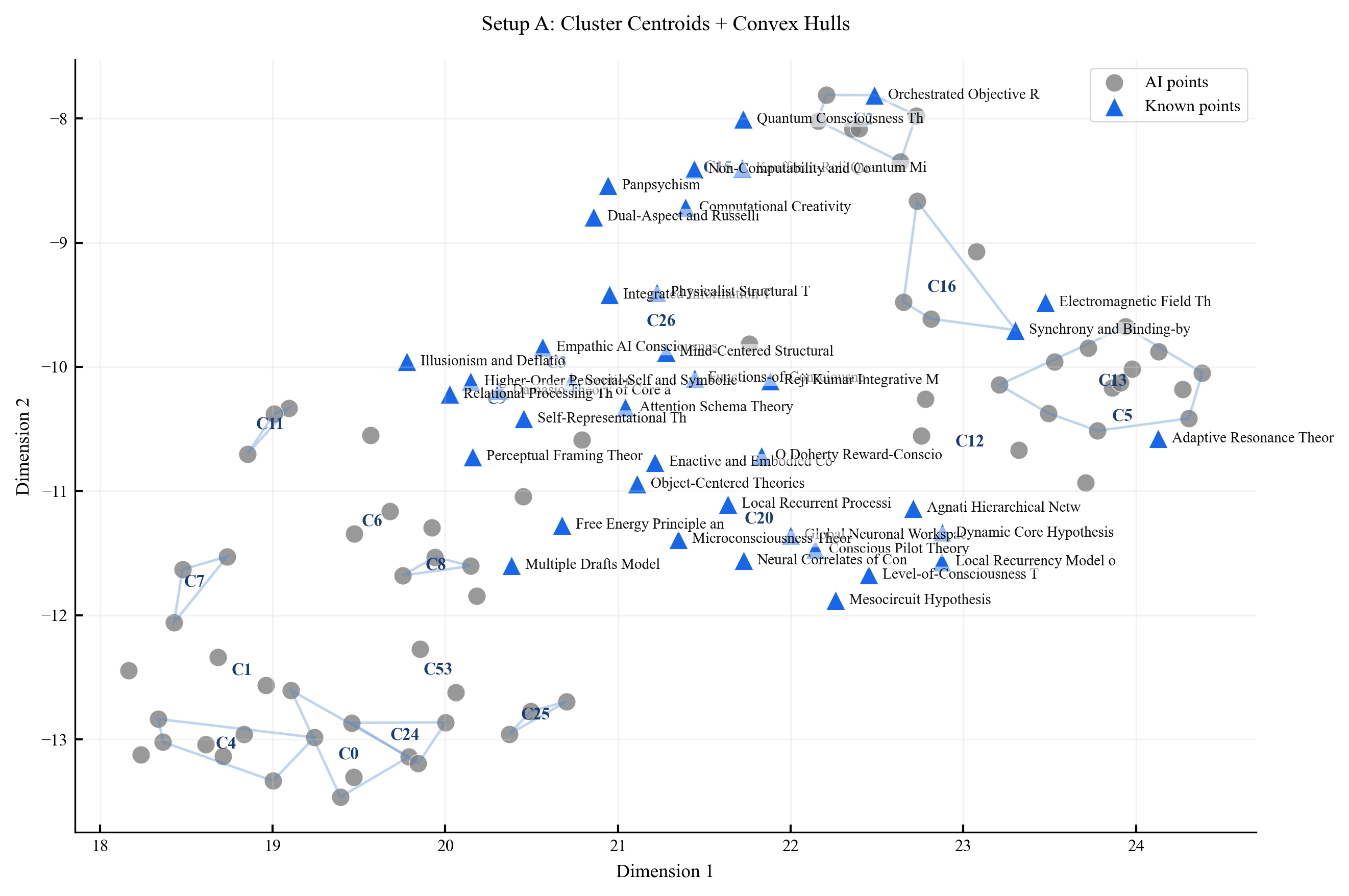
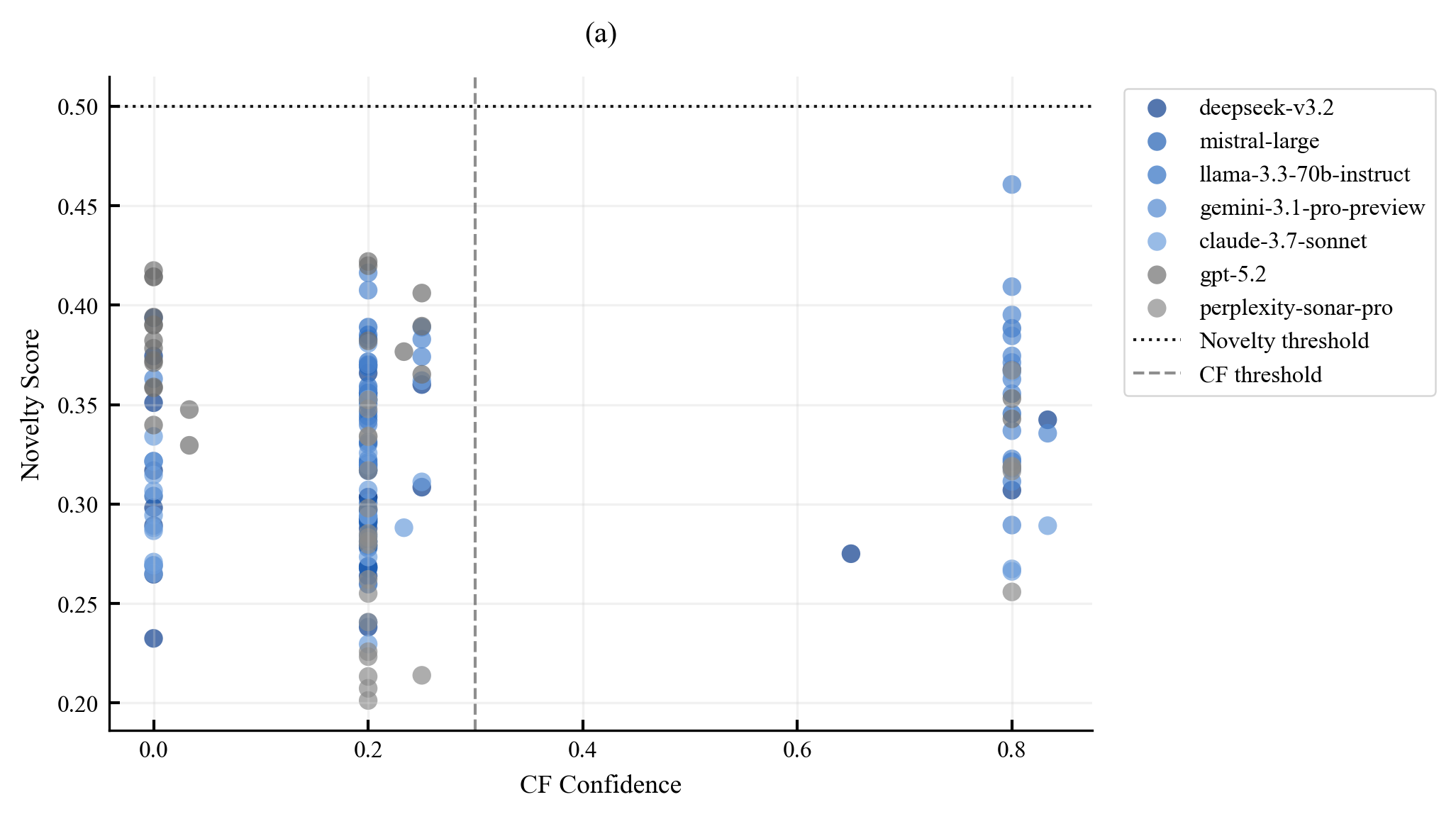
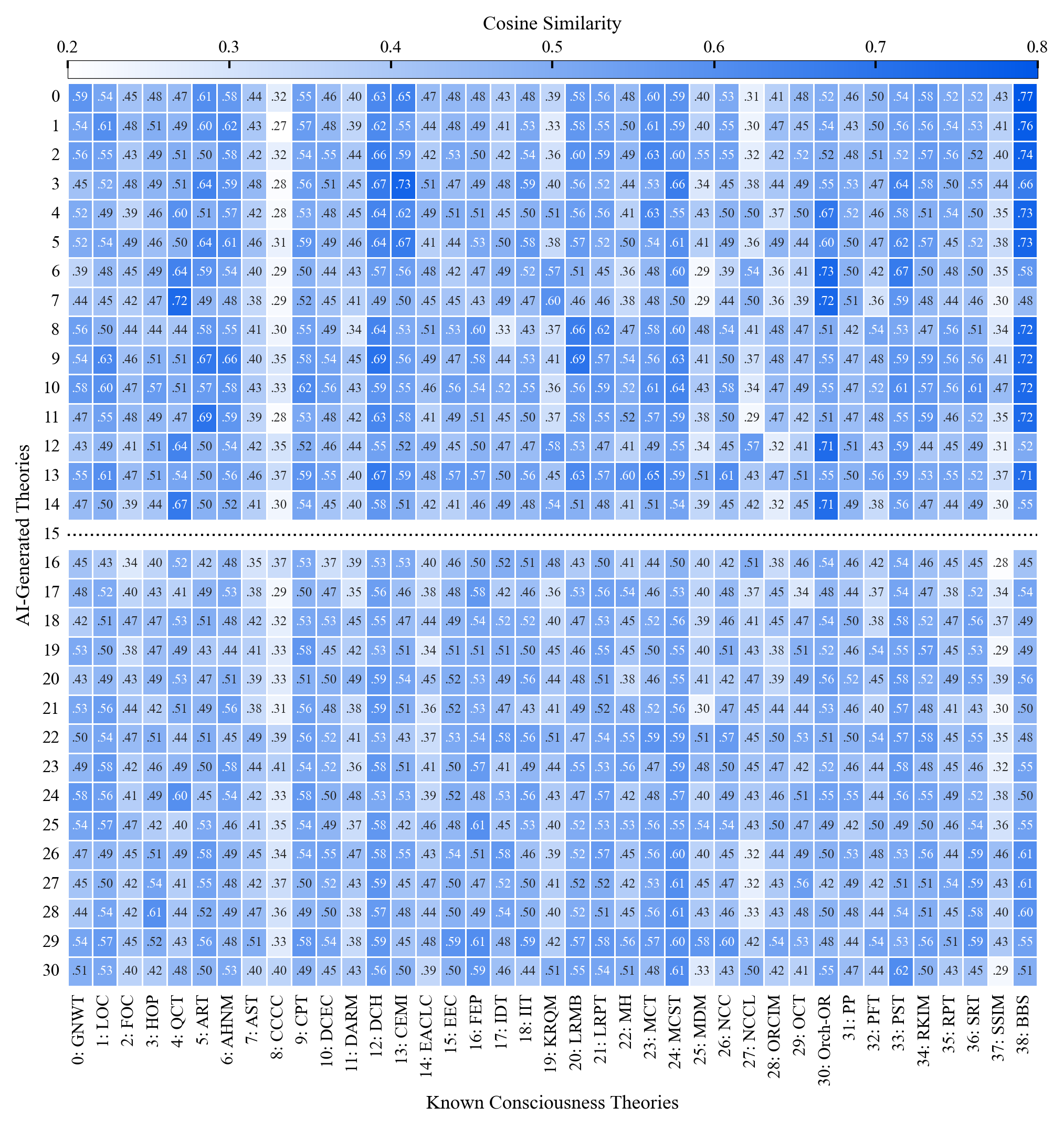
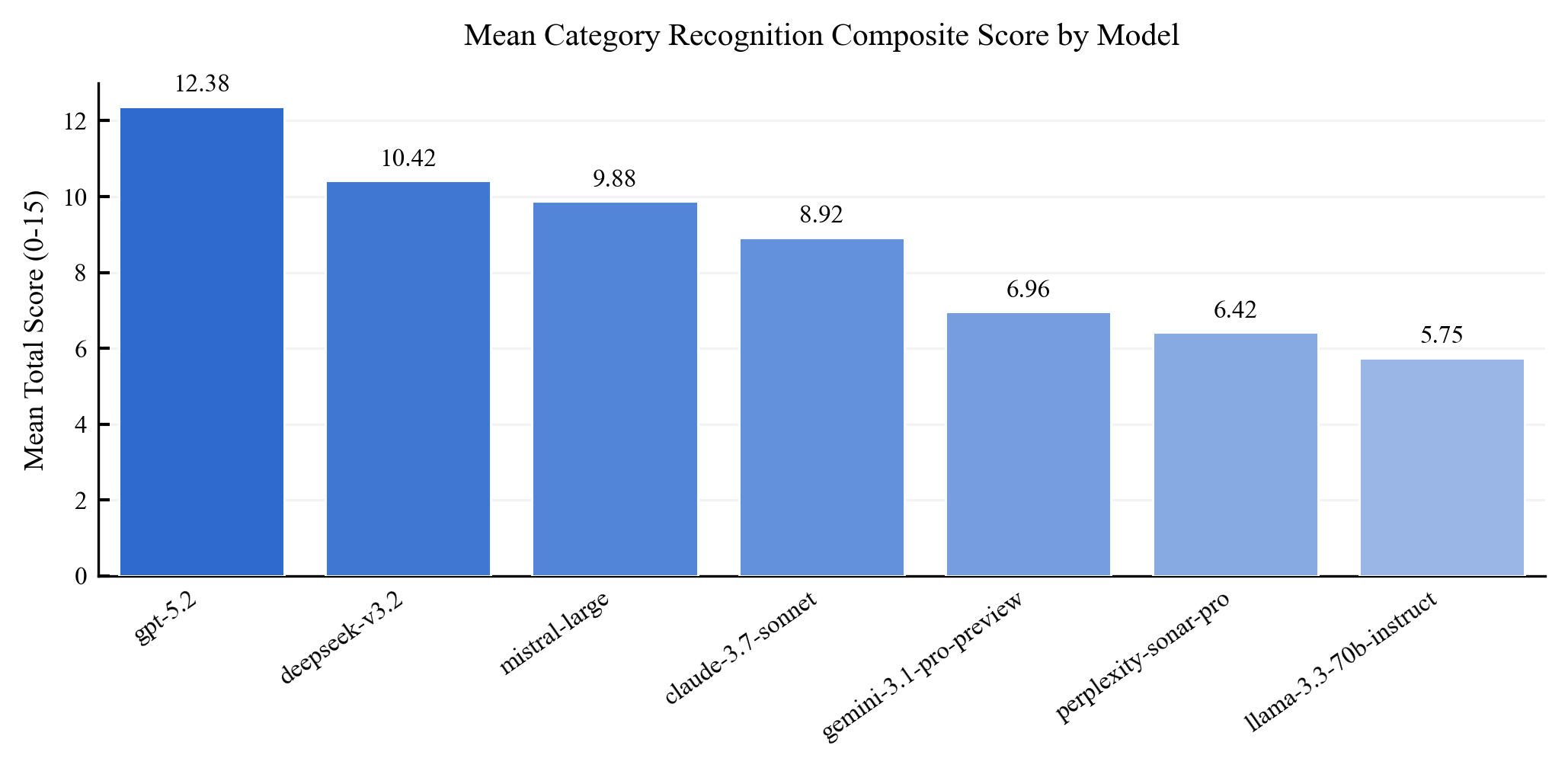
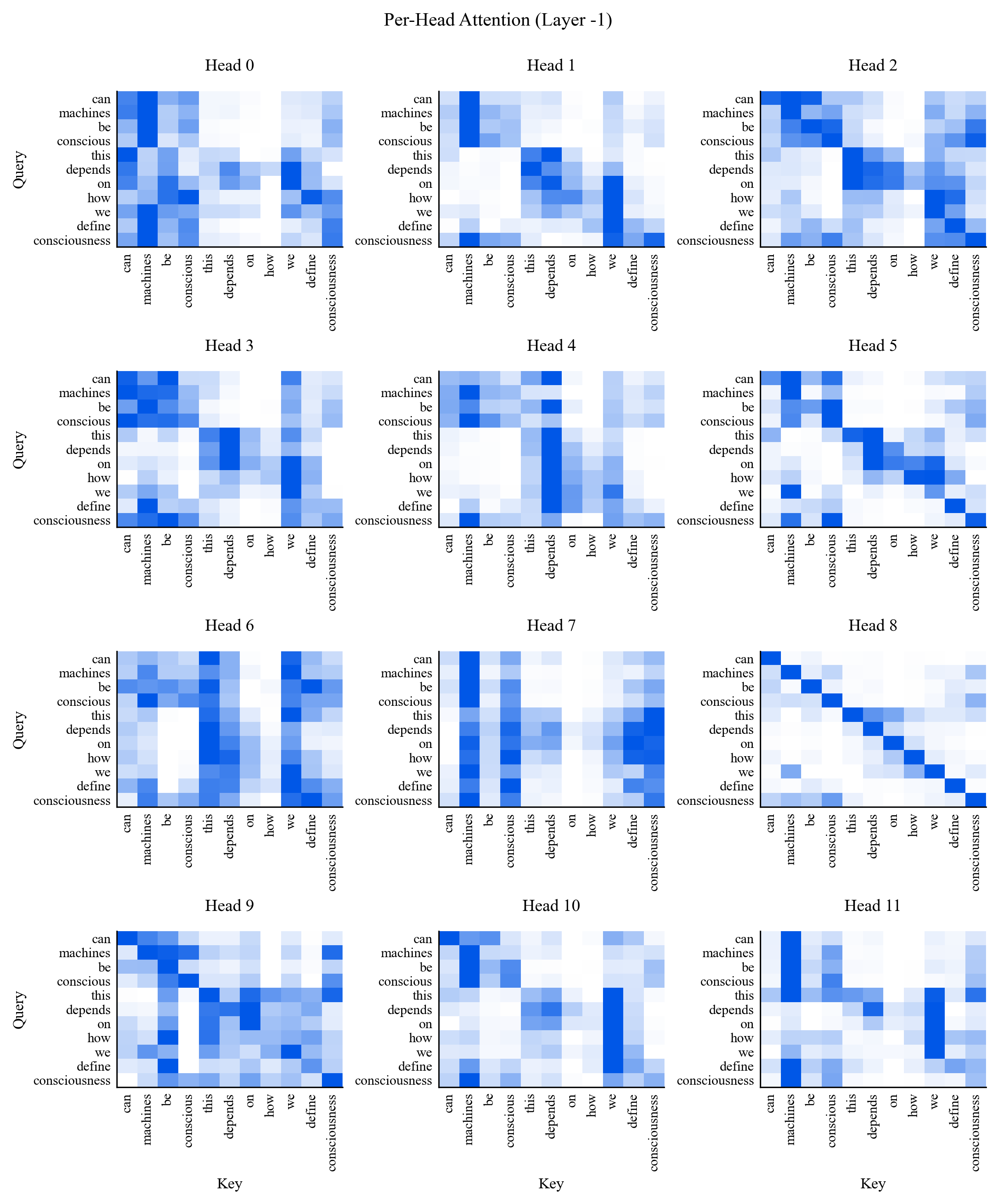
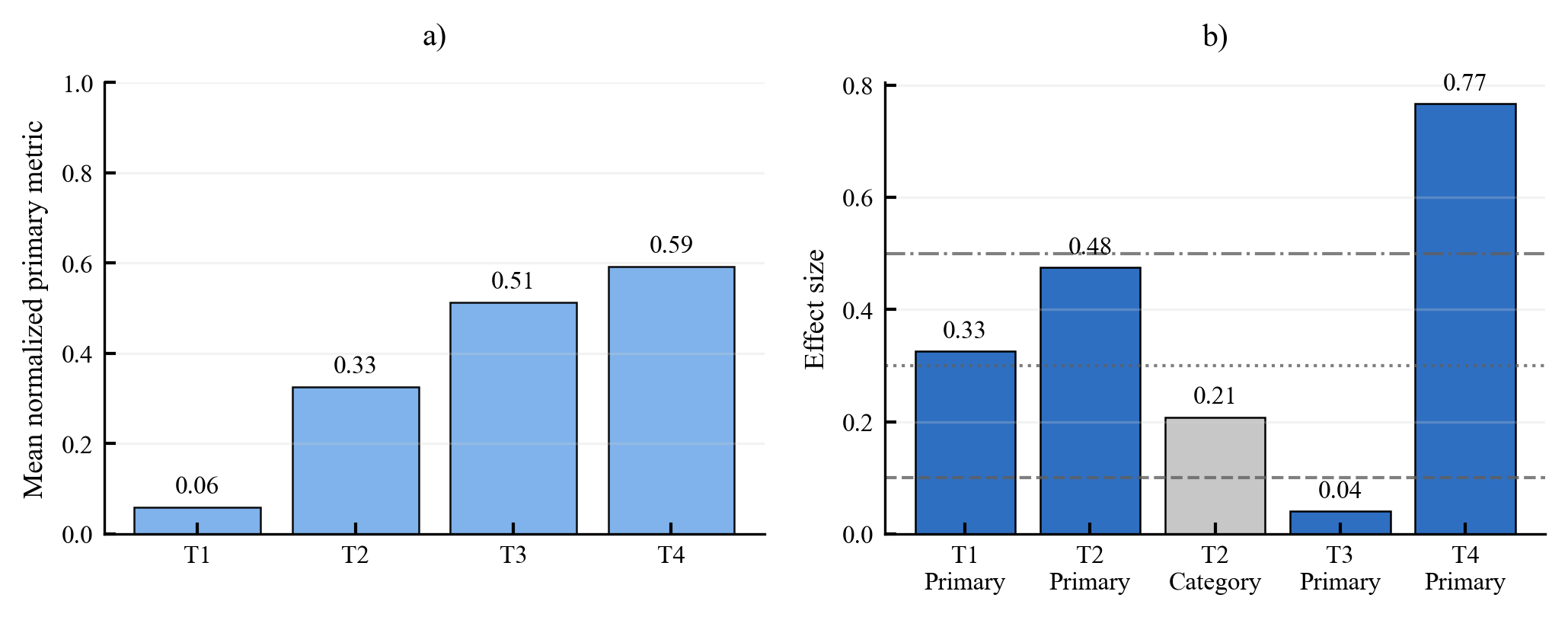
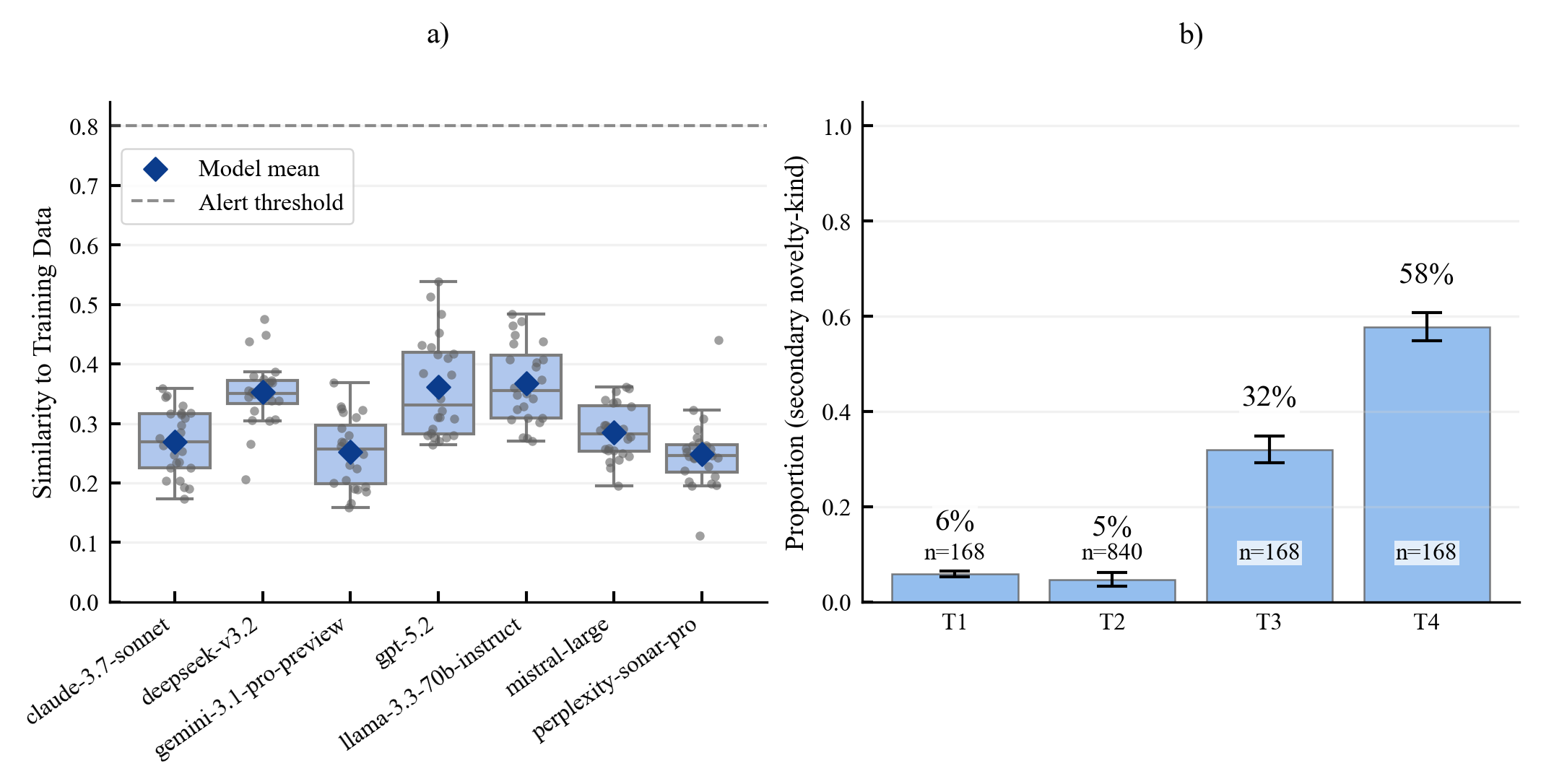
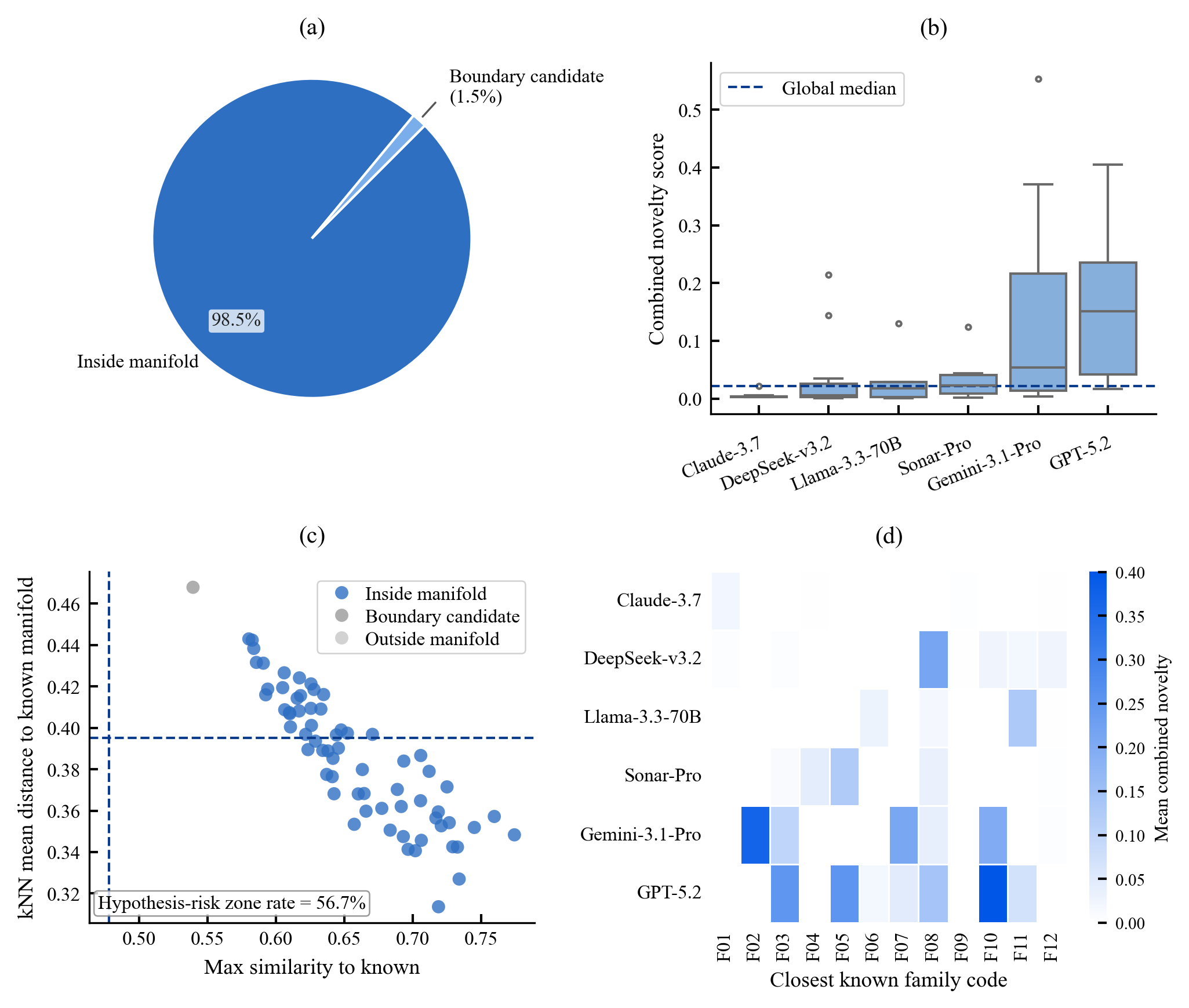
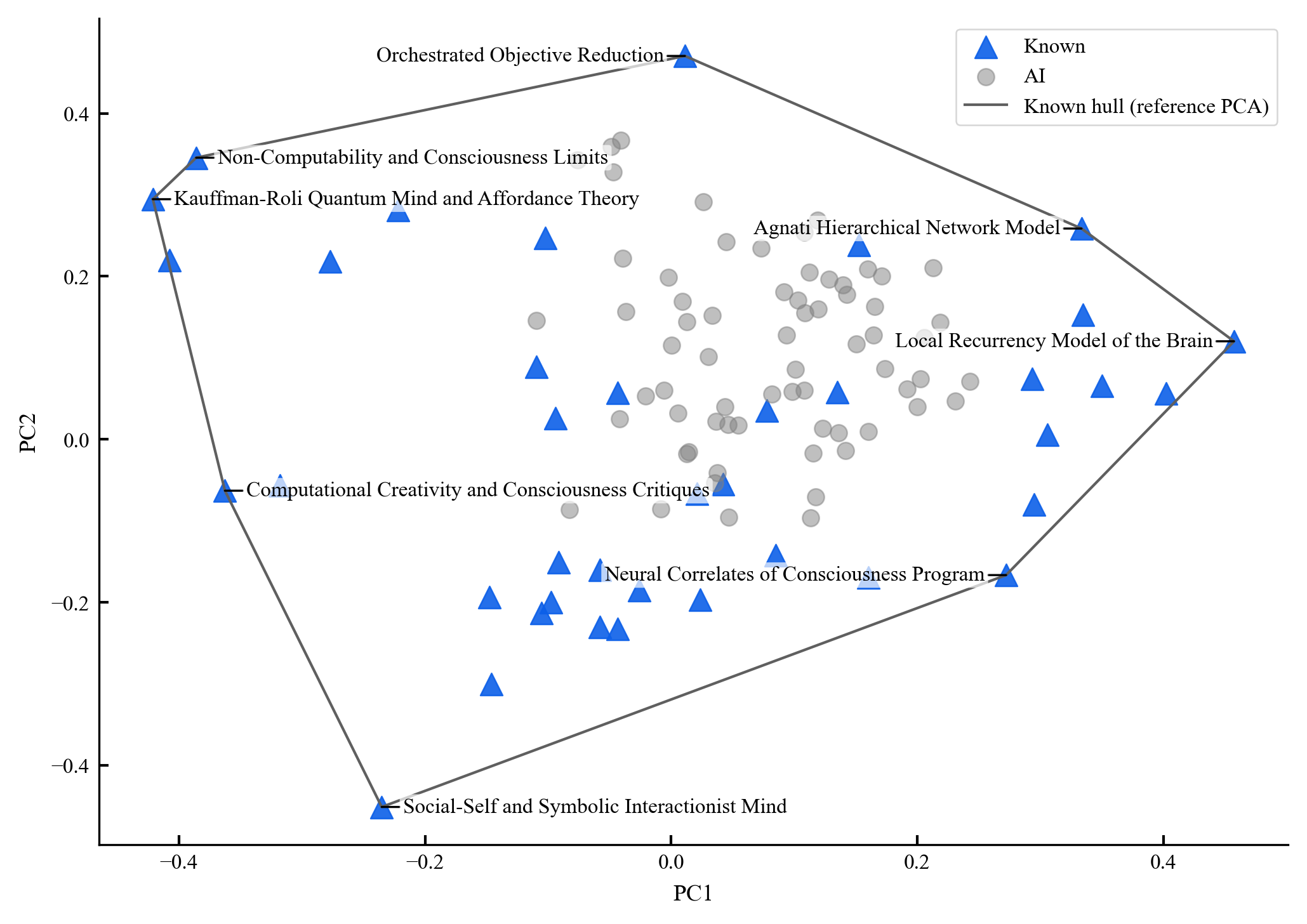
Existing AI capability assessments rely on performance benchmarks without distinguishing surface novelty (recombination) from ontological novelty (genuine representational extension). No formal theorem characterised this boundary prior to this work.
⚖️ Societal Implications
Inflated claims of machine creativity undermine accountability structures, distort policy, and erode the human authority necessary for responsible AI deployment. A rigorous empirical basis is essential.